Introducción al Buffer Overflow - Ejercicios de Protostar stack0 y stack1
-
¿Qué es un Buffer Overflow?
Cuando un programa se ejecuta en el sistema, este almacena un espacio de memoria para su ejecución (pila). Esta pila contiene las variables y datos que se van generando con la ejecución de dicho programa. Cuando ocurre un error de desbordamiento en este, y los datos que se almacenan en el buffer de la pila exceden su capacidad máxima, estos datos extras comienzan a sobreescribir otras secciones de la memoria, generando un fallo, dado que el programa no sabe qué hacer a continuación.
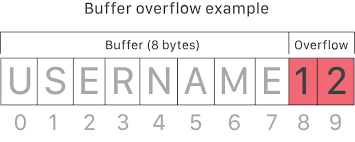
Empleando la imagen anterior, se observa cómo se tiene un buffer de tamaño específico (8 bytes). Si el programa, por una serie de razones como uso de funciones vulnerables o una falta de sanitización de los datos de entrada, introduce datos en dicho buffer con una longitud mayor a los 8 bytes, entonces comenzará a sobreeescribir otras secciones de la memoria, más concretamente, la dirección de retorno del programa (EIP), es decir, la siguiente instrucción que debe ejecutar el programa. Como se ha sobreescrito, el programa generalmente crashea al no saber cómo continuar su ejecución.
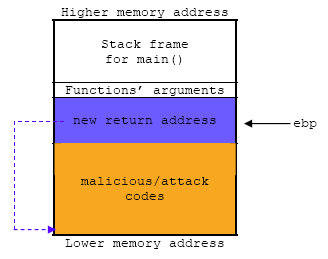
Pero, ¿qué pasaría si podemos aprovechar esta vulnerabilidad para sobreescribir en el EIP la dirección de memoria de una instrucción que queramos ejecutar en el sistema? Este es el objetivo de los ataques por Buffer Overflow, inyectar código malicioso en alguna parte de la memoria, y luego tratar de sobreescribir el EIP para que apunte a dicho código malicioso. De esta forma, el buffer se desborda, el programa continua su secuencia de ejecución por donde nosotros le indicamos, y vulneramos la máquina víctima.
Nota: Para continuar con el desarrollo de las actividades, es necesario contar con un conocimiento básico de programación en C y en lenguaje ensamblador. Así como lenguaje Python para el desarrollo de scripts y un conocimiento de comandos en Linux básico.
-
Para empezar, es necesario descargar e instalar la máquina virtual de Protostar para llevar a cabo los ejercicios.
https://www.vulnhub.com/entry/exploit-exercises-protostar-v2,32/
-
Su instalación en VMWare se da creando una nueva máquina, empleando una configuración típica:
Seleccionamos “Installer disk image file” y buscamos la ISO que descargamos:
Como sistema operativo seleccionamos Linux y una distribución Debian 5 (de 32 bits):
Introduce el nombre que le darás a la máquina y la ruta donde se guardarán los archivos. En el siguiente paso puedes ponerle a la máquina un almacenamiento de 1 GB, no necesita más (a pesar de que VMWare lo recomiende):
En el siguiente apartado, selecciona “Customize Hardware”
Como memoria, la máquina no requiere más de 128 MB:
Este último paso es opcional, y depende de cómo quieras trabajar con la máquina. Puedes llevar a cabo los ejercicios desde la misma terminal de esta, o bien, conectarte vía SSH por medio de una terminal. Si decides trabajar por la segunda vía, entonces también deberás configurar la parte de red de la máquina a una conexión Bridged:
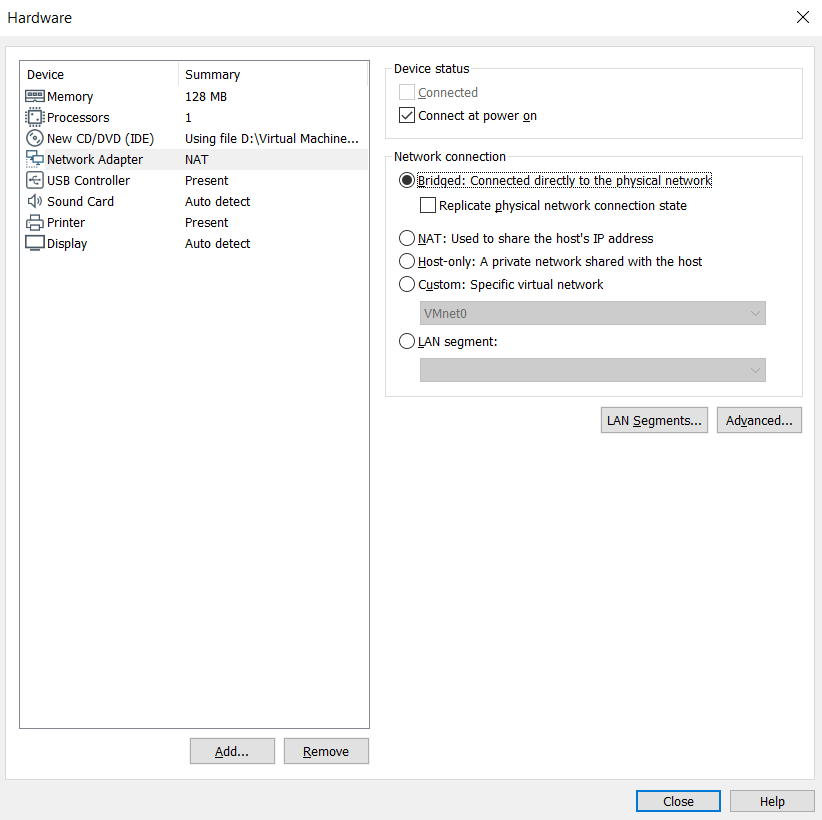
Esa es toda la configuración que requiere la máquina, ahora, podemos arrancarla.
-
Como nosotros vamos a trabajar con una conexión SSH a la máquina, primero nos conectamos por medio del cmd de Windows:
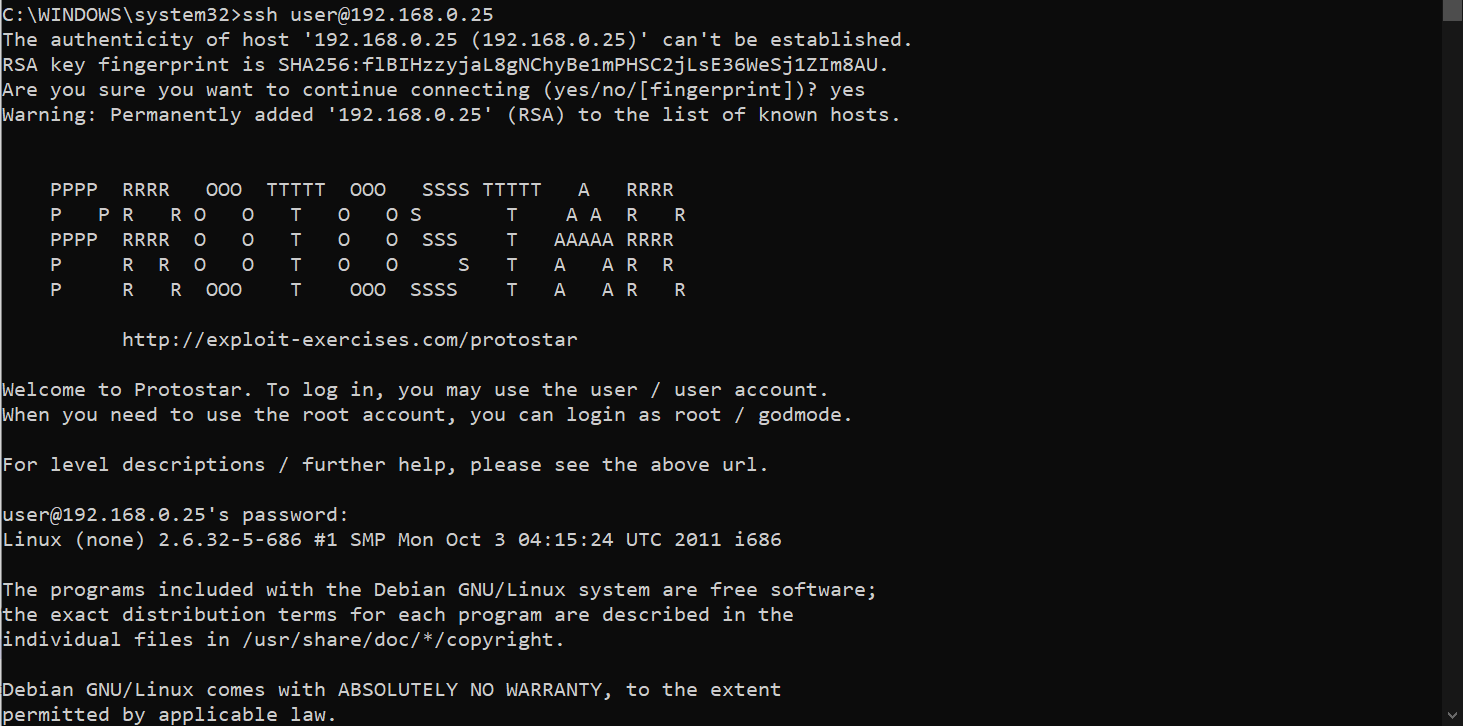
Las credenciales de la máquina son:
Para usuario normal user:user Para usuario root root:godmode -
Como introducción al desbordamiento del buffer, tenemos el binario stack0, el cual tiene el siguiente código fuente:
#include <stdlib.h> #include <unistd.h> #include <stdio.h> int main(int argc, char **argv) { volatile int modified; char buffer[64]; modified = 0; gets(buffer); if(modified != 0) { printf("you have changed the 'modified' variable\n"); } else { printf("Try again?\n"); } }Este código es muy sencillo. Básicamente, crea una variable llamada buffer con un tamaño fijo de 64 bytes. Crea una variable llamada modified, la cual hardcodea con el valor de 0 y emplea la función gets para obtener la entrada del usuario y almacenarla en la variable buffer. Aquí se presenta la vulnerabilidad del programa, dado que la función gets no mide la longitud de la entrada, ni si “cabe” en la variable destino. C recomienda usar en estos casos la función fgets. Como no verifica si la entrada sobrepasa la capacidad de la variable, cuando esta exceda los 64 bytes, ocurrirá un error de desbordamiento.
Como podemos observar en el código, la primer variable en ser declarada es modified, seguida de buffer. Esto implica además que en este orden estarán declaradas en la memoria:
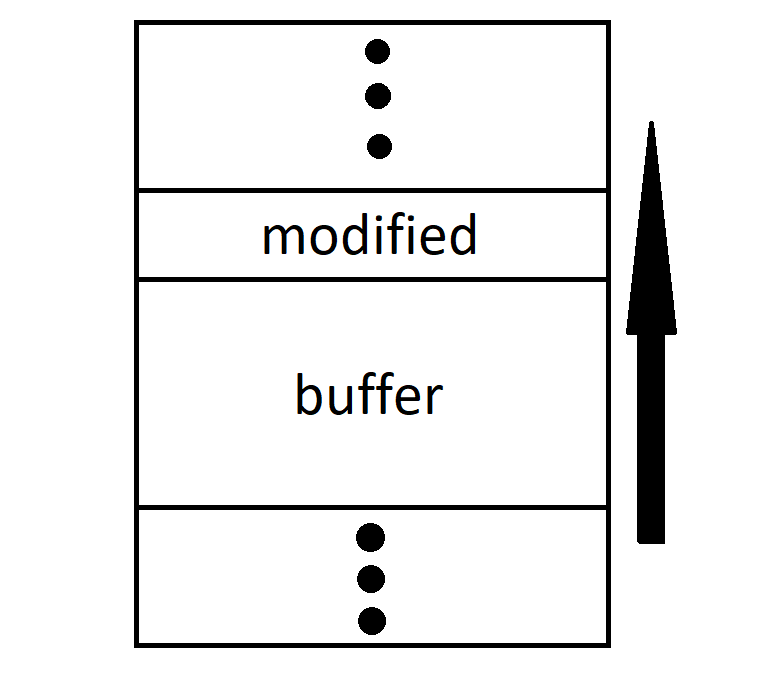
Se observa cómo la variable modified está arriba en memoria que la variable buffer. Por lo tanto, en cuanto se desborde la segunda, la primera comenzará a ser sobreescrita con los datos restantes.
El código continúa con una condicional, en la que se verifica que el valor de modified siga siendo cero. Como se puede observar, en el programa no sucede alguna acción que modifique este valor, por lo que técnicamente siempre tendría que caer en el caso else de: Try again?. Por lo tanto, debemos encontrar una forma de modificar el valor de esta variable. ¿Cómo realizar este paso si no podemos modificar el código fuente?
La respuesta está dada en la forma en que se declararon las variables en memoria. La variable modified puede ser modificada si la sobreescribimos directamente en memoria, por lo que la única forma de hacerlo, es aplicando un desbordamiento en la variable buffer. Observemos primero cómo se comporta el programa si lo ejecutamos con una entrada que no exceda el tamaño de la variable buffer (64 bytes):

En el caso anterior, se ejecuta el programa con 64 letras “A” como argumento. Como podemos ver, la aplicación se ejecuta correctamente, y nos devuelve el mensaje para cuando la variable modified vale cero. Pero qué pasaría si ahora, en lugar de introducir el número exacto de letras que tiene como límite la variable, introducimos solamente una más (es decir, 65):

En este caso, el programa se ejecuta y lanza el mensaje para cuando la variable modified no vale cero, porque al sobrepasar la capacidad de la variable buffer, hemos pasado una letra A (41 en hexadecimal) al espacio de memoria que almacena el valor de modified, por lo tanto, deja de valer cero para valer, en este caso “A”.
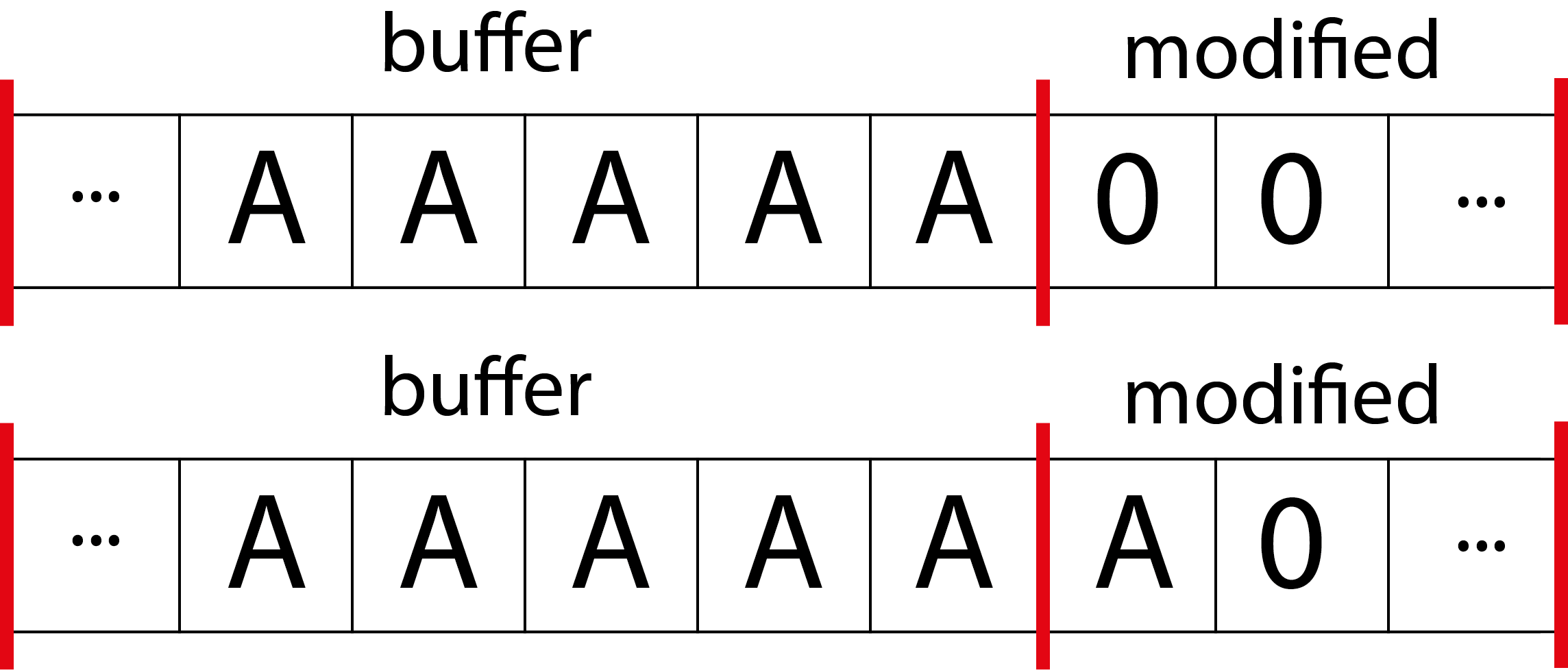
En la parte superior vemos una representación de la memoria antes del desbordamiento, y en la parte inferior después de aplicar un desbordamiento, como podemos ver, la letra “A” extra sobreescribe cualquier contenido que tuviera modified, cambiando su valor.
Con esto hemos completado el primer ejercicio. Sigamos con el segundo, que corresponde al binario stack1.
-
Para el segundo ejercicio, el binario stack1 cuenta con el siguiente código fuente:
#include <stdlib.h> #include <unistd.h> #include <stdio.h> #include <string.h> int main(int argc, char **argv) { volatile int modified; char buffer[64]; if(argc == 1) { errx(1, "please specify an argument\n"); } modified = 0; strcpy(buffer, argv[1]); if(modified == 0x61626364) { printf("you have correctly got the variable to the right value\n"); } else { printf("Try again, you got 0x%08x\n", modified); } }Lo que realiza el código es algo similar al del primer ejercicio. Primero declara las mismas dos variables del caso anterior: modified y buffer. Posteriormente, simplemente verifica que el usuario haya introducido un argumento como entrada. Por último, se valida por medio de un condicional si la variable modified ahora vale un valor específico, en este caso 0x61626364. Si hemos entendido el primer ejercicio por completo, veremos que no hay mayor complicación para resolver este, dado que ahora, en vez de simplemente sobreeescribir modified con cualquier valor, debemos hacerlo con un valor específico.
De igual manera, la variable buffer tiene un tamaño fijo de 64 bytes, por lo que intentamos ejecutar el programa con esta cantidad de información. Se emplea Python para imprimir las 64 A sin necesidad de escribir una por una:

Vemos que el programa nos devuelve la cadena de texto correspondiente a cuando modified no vale 0x61626364. En esta cadena nos devuelve además el valor que tuvo dicha variable al finalizar el programa, por lo que, si introducimos una “A” de más como argumento, veremos lo siguiente:

En esta ocasión, la variable modified no vale 0x00000000, sino 0x00000041. Recordemos que el valor en hexadecimal de la letra “A” es 41, por lo tanto, vemos que podemos sobreeescribir la variable con lo que nosotros le indiquemos. Intentamos seguir sobreescribiendo para observar cómo es posible llenar los 4 bytes que tiene de tamaño la variable:

De hecho, si ahora intentamos sobreescribir la variable con otros caracteres, vermos cómo estos son presentados en su representación hexadecimal. En este caso, se introdujo una letra “B” y una letra “C”, como podemos observar, estas son introducidas en un orden inverso al que se podría esperar. A esta notación se le conoce como big-endian, donde, de acuerdo a la posición que ocupe el caracter en la memoria, será el espacio en el que se almacene (en este caso, en la variable modified):
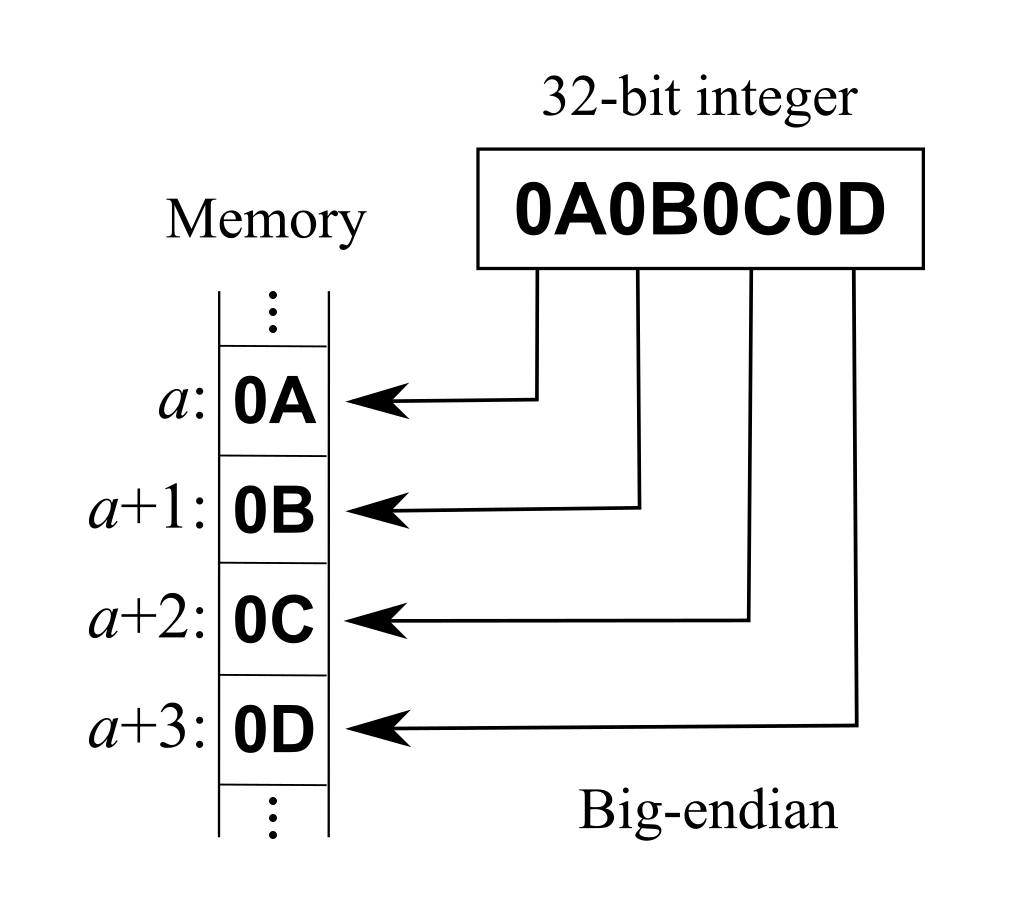

Como requerimos que modified valga 0x61626364, primero vemos a qué letras (o caracteres) corresponden estos códigos hexadecimales. Con ayuda de “man ascii” en Linux, vemos que corresponden a las siguientes letras:
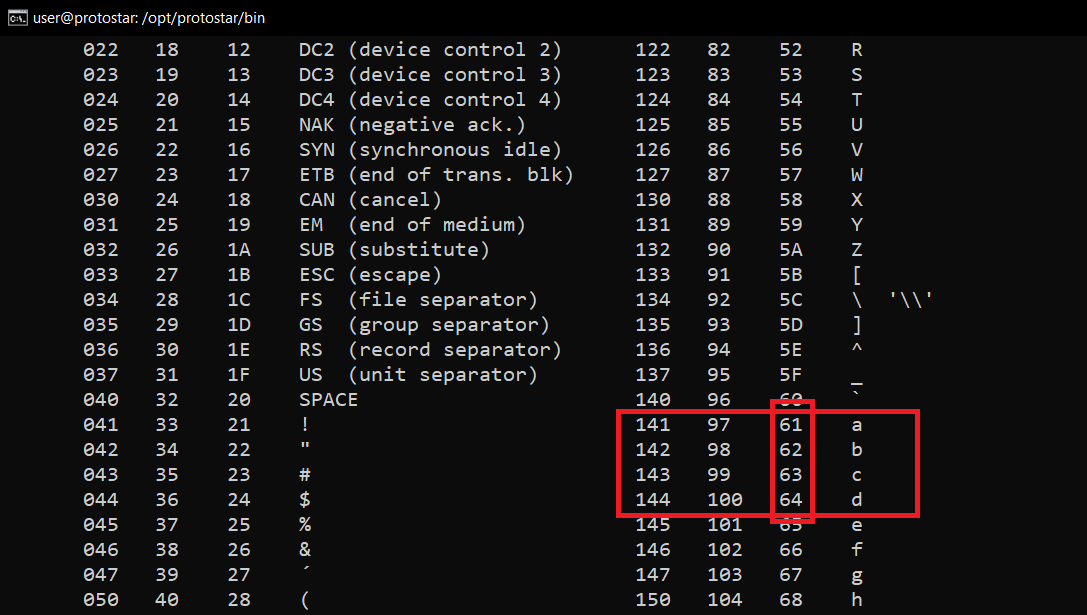
61 - a 62 - b 63 - c 64 - dSiendo así, y teniendo un formato big-endian, introducimos los caracteres como la parte del argumento de entrada que sobreescribirá a modified de la siguiente manera:
./stack1 $(python -c "print('A'*64+'d'+'c'+'b'+'a')")Si ejecutamos de esta manera el binario, veremos ahora sí la cadena de texto que ocurre cuando la variable modified vale 0x61626364.

En la siguiente entrada, veremos cómo resolver el tercer ejercicio de esta serie proporcionada por Protostar para introducirnos en el mundo del Buffer Overflow.